The Procedural Reality Beneath Object Oriented Programs
Many software engineers are taught object-oriented programming (OOP) with little regard to what the machine is actually doing - a common failure of university curricula. This in turn creates an attitude where a mere programming paradigm is treated as a divine abstraction offered to us by the deities who bestow us with programming languages.
I find that unacceptable. No abstraction is sacred. All object-oriented techniques can be mapped to procedural code with structs and function pointers. More engineers should be aware of this, and students, in particular, should not be shielded from this reality.
To break the illusion, I will convert typical object oriented Java code into C code while retaining the object-oriented style. In fact, early C++ was a transpiler that translated those OOP constructs into plain C code.
I have my own criticisms of OOP as paradigm, but this is about conversion, not policing how code should be written.
We’ll use a shape class hierarchy as an example. The example is simple, yet captures many important features. Here’s the Java code:
class Shape {
double x, y;
Shape(double x, double y) {
this.x = x;
this.y = y;
}
void draw() {
System.out.println("Drawing at (" + this.x + ", " + this.y + ")");
}
double area() {
return 0;
}
void translate(double dx, double dy) {
this.x += dx;
this.y += dy;
}
}
class Circle extends Shape {
double radius;
Circle(double x, double y, double radius) {
super(x, y);
this.radius = radius;
}
@Override
double area() {
return Math.PI * radius * radius;
}
void spin() {
System.out.println("Spinning this circle. Btw it has radius " + this.radius);
}
}
class Rectangle extends Shape {
double width, height;
Rectangle(double x, double y, double width, double height) {
super(x, y);
this.width = width;
this.height = height;
}
@Override
double area() {
return width * height;
}
}
What’s a “class” anyway
A class is the basic encapsulation unit in OOP. It combines state and behavior. Capturing state is easy; just use a struct:
typedef struct {
double x;
double y;
} Shape;
To capture behaviour, we may be tempted to use functions like so:
void shape_translate(Shape *shape);
void shape_draw(Shape *shape);
double shape_area(Shape *shape);
But that won’t work at all, because subclasses that extend Shape may override any of those functions with their own implementation. Instead, we want the implementation to be dynamic. That is, two different Shape structs (say one is a circle and the other is a rectangle) will have different implementations for, say, shape_area(). To allow for this level of flexibility, we’ll use function pointers instead:
typedef struct Shape {
double x;
double y;
void (*translate)(struct Shape *this, double dx, double dy);
void (*draw)(struct Shape *this);
double (*area)(struct Shape *this);
} Shape;
Notice how “behaviour of a class” is actually just a special kind of state (a mere pointer), nothing magical about it. We can provide a default implementation by calling an initialization function that sets defaults for us.
void translate(struct Shape *this, double dx, double dy) {
this->x += dx;
this->y += dy;
}
void draw(struct Shape *this) {
printf("Drawing at (%g, %g)", this->x, this->y);
}
double area(struct Shape *this) {
return 0;
}
// our constructor
void init_shape(Shape *shape, double x, double y) {
shape->x = x;
shape->y = y;
shape->translate = translate;
shape->draw = draw;
shape->area = area;
}
Here, we define the default implementations and assign them in the initialization function init_shape().
You can think of init_shape() as a constructor, except it does not allocate memory for the shape as it’s done in actual OOP languages. We could’ve simply called malloc() and returned a pointer, but this approach forces us to heap-allocate all our objects. This is partially what C++ calls “Resource Acquisition Is Initialization” (RAII), where object construction often goes hand-in-hand with resource allocation, typically on the heap. I say partially because RAII in C++ has other uses.
P.S not using RAII makes our implementation less faithful to typical OOP code, but we’re already peeling abstractions, and we might as well experiment with different approaches. An advantage of this method is that it decouples allocation from initialization. Depending on the problem, we might greatly improve our performance or simplify code if we allocate our objects on the stack or even use a different kind of allocator like an arena allocator. This time, resource acquisition is not initialization (RAINI).
Alright, back to the code. Right now, we can override a shape’s methods manually by changing what the function pointers point to. We might be tempted to try to write:
void circle_area(Shape *this) { /* snip */ }
void rectangle_area(Shape *this) { /* snip */ }
int main() {
Shape circle; // allocated on the stack
Shape rectangle;
init_shape(&circle, 0, 0);
init_shape(&rectangle, 0, 0);
// override
circle.area = circle_area;
rectangle.area = rectangle_area;
// use
circle.area(&circle);
rectangle.area(&rectangle);
return 0;
}
That’s better than nothing, but won’t really work:
A) The circle_area() and rectangle_area() functions only take a Shape*, and thus, we can only use Shape’s fields in our implementation (so only access to x, y positions and the other function pointers).
B) We cannot add additional behaviour to our class. We want to be able to add a new spin() method to Circle.
It’s impossible to compute the area of circle without knowing its radius or a rectangle without knowing the width and height. Thus, we need to extend a shape to add more fields or behaviour. Or in other words, we need to implement inheritance.
Inheritance
We can implement inheritance in C by using composition. We declare the super class as the first member of the struct, and then add our extra fields and function pointers below:
typedef struct Circle {
Shape super;
double radius;
void (*spin)(struct Circle *this);
} Circle;
typedef struct Rectangle {
Shape super;
double width;
double height;
} Rectangle;
The reason why we need Shape super to be the first member will become clear later.
We now have everything we need to implement circles and rectangles that work. Since the code for circles and rectangles is very similar, we’ll focus on circles from now on. We added a new method to Circle by adding an additional function pointer, we have to initialize that function pointer in the circle’s “constructor”
// A new method for circle
void spin(Circle *this) {
printf("Spinning this circle. Btw it has radius %g\n", this->radius);
}
// Circle's constructor
void init_circle(Circle *this, double radius, double x, double y) {
init_shape(&this->super, x, y); // calling the "super constructor"
this->spin = spin; // registering a new method
this->radius = radius; // data unique to Circle
}
The init_circle() function acts like a constructor for Circle. Notice how it internally calls init_shape(), which acts like a “super” constructor. We then set the function pointers of our implementation. Next, we’ll override existing behaviour by changing the function pointers of the underlying Shape struct embedded within each subclass. Example:
#define PI 3.14159
// Overriding a method for circle
double circle_area(Shape *this) {
// woah! This is like downcasting in Java.
Circle *circle = (Circle *) this;
return PI * circle->radius * circle->radius;
}
void spin(Circle *this) { /* snip */}
void init_circle(Circle *this, double radius, double x, double y) {
init_shape(&this->super, x, y);
this->spin = spin;
this->super.area = circle_area; // overriding an existing method
this->radius = radius;
}
You might’ve noticed that circle_area()’s signature takes a Shape * instead of Circle *, this is because super->area expects a Shape * parameter and we have to match its signature. In order to turn the Shape * argument into a Circle * (to access the radius), we cast the Shape * into a Circle *.
This works because C guarantees that the address of a struct is the same address of its first member. Take a look at this illustration:
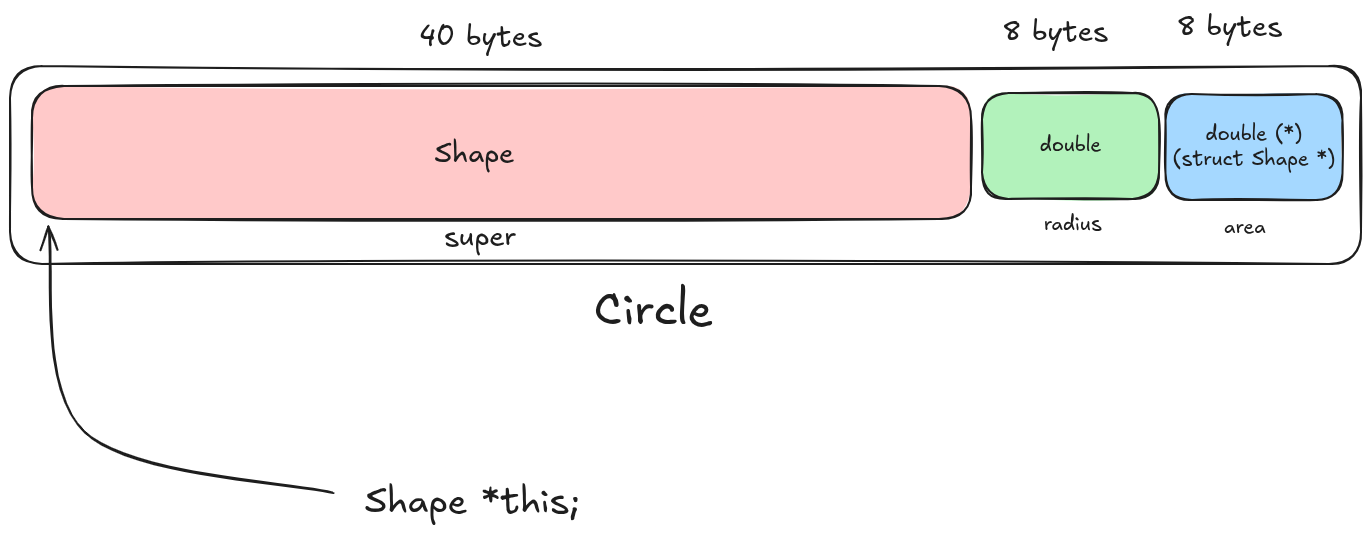
Since super is the first member of Circle, a pointer to super is the same thing as a pointer to the entire circle, and thus we can safely cast between the two. This is why we have made super the first element in Circle. Otherwise we’ll have to do pointer arithmetic to make the pointer point to the Circle (or use a macro like container_of(). More on that later).
The compiler knows that this pointer is pointing to a Shape in memory. Additionally, we, the programmers know that Shape is also a circle, and this is pointing to circle.super, but the compiler doesn’t know this. It won’t allow us direct access to a circle’s fields unless we ask the compiler (through casting) to treat this as a pointer to a circle instead. The underlying data is the same, the pointer has the same value, there’s no runtime cost associated with the cast. The compiler trusts us that we know what we are doing (and we do!).
Our implementation is complete. We can now write similar code for rectangles, and then try our class hierarchy out. Here’s the full code:
#include <stdio.h>
#define PI 3.14159
/////////////////
// Shape "class"
/////////////////
typedef struct Shape {
double x;
double y;
void (*translate)(struct Shape *this, double dx, double dy);
void (*draw)(struct Shape *this);
double (*area)(struct Shape *this);
} Shape;
void translate(struct Shape *this, double dx, double dy) {
this->x += dx;
this->y += dy;
}
void draw(struct Shape *this) {
printf("Drawing at (%g, %g)\n", this->x, this->y);
}
double area(struct Shape *this) { return 0; }
// shape constructor
void init_shape(Shape *shape, double x, double y) {
shape->x = x;
shape->y = y;
shape->translate = translate;
shape->draw = draw;
shape->area = area;
}
/////////////////
// Circle "class"
/////////////////
typedef struct Circle {
Shape super;
double radius;
void (*spin)(struct Circle *this);
} Circle;
void spin(Circle *this) {
printf("Spinning this circle. Btw it has radius %g\n", this->radius);
}
// Overriding a method for circle
double circle_area(Shape *this) {
Circle *circle = (Circle *) this;
return PI * circle->radius * circle->radius;
}
void init_circle(Circle *this, double radius, double x, double y) {
init_shape(&this->super, x, y);
this->spin = spin;
this->super.area = circle_area; // overriding an existing method
this->radius = radius;
}
/////////////////////
// Rectangle "class"
////////////////////
typedef struct Rectangle {
Shape super;
double width;
double height;
} Rectangle;
double rectangle_area(Shape *this) {
Rectangle *rect = (Rectangle *) this;
return rect->width * rect->height;
}
void init_rectangle(Rectangle *this, double width, double height, double x, double y) {
init_shape(&this->super, x, y);
this->super.area = rectangle_area;
this->width = width;
this->height = height;
}
int main() {
Circle circle;
Rectangle rectangle;
init_circle(&circle, 10, 0, 0);
init_rectangle(&rectangle, 5, 6, 0, 0);
// each area "method call" points to a different function
printf("circle area: %g\n", circle.super.area(&circle.super)); // ~ 314
printf("rectangle area: %g\n", rectangle.super.area(&rectangle.super)); // 30
// let's also spin the circle for fun
circle.spin(&circle);
}
Our implementation works perfectly fine for small programs or even some large programs. However, imagine we were working on something complex like a graphics engine where we’d have dozens of methods and thousands of shapes everywhere. Assuming a 64-bit machine, each shape takes at least 40 bytes of memory mostly because of the function pointers it has to carry. If we had 10000 shapes, we’d consume 400 KB, and that’s ignoring the other specific fields the subclasses have to store. Each method increases our memory usage by 8 bytes; that’s linear (O(n)) space consumption. One optimization that OOP language use is to store all the function pointers in a separate struct called a “vtable”. Each Shape instance, would then have a pointer to that vtable instead
We can implement vtables like so:
// forward declaration to satisfy the compiler
typedef struct ShapeVTable ShapeVTable;
typedef struct {
double x;
double y;
ShapeVTable *vptr;
} Shape;
typedef struct {
void (*translate)(struct Shape *this, double dx, double dy);
void (*draw)(struct Shape *this);
double (*area)(struct Shape *this);
} ShapeVTable;
Now, any call has to go through the vtable like so: myshape->vptr->area(myshape). We went from consuming 8 bytes per method to now only paying 8 bytes once; no matter how many methods we have (that’s O(1) per-object). Sweet.
The name “vtable” stands for virtual table. A polymorphic method is sometimes called a “virtual function”, and a “vtable” is just a table used to lookup those virtual functions. The downside of using vtables is that you now have to perform two pointer dereference operations. One for the vtable, and one for the function itself.
We’re done. We have converted OOP code into plain C code through clever usage of structs and pointers. Languages that implement OOP features internally use similar techniques, but the underlying concept is the same. Still, we still have a few more things to discuss like multiple inheritance and interfaces. We don’t use them in our Shape’s example, but they’re still part of OOP and we’d like to cover them.
Interfaces and multiple inheritance
Multiple inheritance of classes (not interfaces) is banned in many OOP languages. Even if it’s not banned, you’re strongly encouraged to avoid it. If you find yourself using it, then you’re likely making a mistake you’ll regret, but as mentioned earlier, I’m only interested in mapping OOP code to procedural code, not to police how code should be written, so let’s try it out.
I spent a lot of time trying to think of a good example to code up, but multiple inheritance is so bad that every example I thought of was painful code that I simply felt moral responsibility to not share. Instead, to spare you the pain of asking “When I will ever use this in real code”, I have decided to make up an abstract example detached from reality. We’ll create a class Child that has two parents A and B. We can do this in C by embedding both parents in Child.
typedef struct A {
void (*do_a)(struct A *this);
int x;
} A;
typedef struct B {
void (*do_b)(struct B *this);
int y;
} B;
typedef struct {
A a;
B b;
} Child;
Just like in the circle example, overriding A’s method is easy because we know an instance of A is the first member of Child.
void child_do_a(A *this) {
// downcast just like with Circle
Child *child = (Child *) this;
// use child just fine
}
void child_do_b(B *this) {
// how to downcast????
}
Overriding B is trickier since we only get a pointer to B. You might attempt to use pointer arithmetic to get a pointer to Child.. That would certainly work but its needlessly error prone and annoying to maintain: What happens if we add a new field between A and B? What if the layout changes after a refactor? It would be great if there’s a way for us to ask the compiler to find out the necessary offset for us. Fortunately, there’s a way for us to do this.
offsetof() and container_of()
The offsetof() macro (It’s amazing that a macro has its own Wikipedia page) allows us to get the offset in bytes of a member, from its struct. That is, if we have a structure like this:
struct X {
char a; // offset: 0
int b; // starts at: 4 (due to padding)
int c; // starts at: 8
};
Then we can use offsetof() as follows:
offsetof(X, a) // 0
offsetof(X, b) // 4
offsetof(X, c) // 8
The offsetof() macro is already provided by GCC, Clang, and MSVC. We may simply use it without thinking about the details, but you might wonder how it is implemented. Well, GCC and Clang define it in terms of a compiler built-in, a black box:
#define offsetof(st, m) \
__builtin_offsetof(st, m)
If for whatever reason you find yourself using a compiler that has no offsetoff() macro, then you can define it yourself in a way that slightly breaks the standard:
#define offsetof(st, m) \
((size_t)&(((st *)0)->m))
Essentially you pretend 0 is a pointer to st, then try to access the member m, and use the & operator to get the address. Finally cast it to size_t to treat it as a plain number. The reason this breaks the standard is because you’re technically dereferencing a null pointer. However most compilers allow it because they recognize you’re not actually evaluating and reading from the pointer, but merely using it to obtain an address, a simple number. The compiler will not emit code that reads such memory. However, this is still technically not allowed by the standard, but plenty of compilers don’t care and many projects actively rely on this behaviour.
One more thing, technically the hand-rolled definition of offsetof() should be this:
#define offsetof(st, m) \
((size_t)((char *)&((st *)0)->m - (char *)0))
According to Wikipedia, this seemingly useless subtraction is needed because the C standard does not guarantees that the internal memory representation of NULL is 0. Even if it works in practice. I don’t know about you, but I find a twisted sense of thrill when I’m sitting at the edge of the standard.
We will use the offsetof() macro to to define the container_of() macro. This macro is also used by the Linux kernel (though with a different definition that relies on a GCC extension). It’s defined like this:
#define container_of(ptr, type, member) \
((type *)((char *)(ptr) - offsetof(type, member)))
Given a pointer ptr, a type and a member, it will subtract the necessary offset from ptr such that it points to the given type. Basically It says “I know that ptr is actually just a pointer to a member of type. I want a pointer to the containing struct”.
This is exactly what we need in order to downcast a superclass into a subclass. We don’t have to rely on the superclass being the first member in the struct, it can be anywhere, and container_of() will give you the correct pointer anyway. This means we can override methods like this:
void child_do_a(A *this) {
Child *child = container_of(this, Child, a);
// use child just fine
}
void child_do_b(B *this) {
Child *child = container_of(this, Child, b);
// use child just fine
}
Splendid! We now have the necessary machinery needed to perform multiple inheritance. Using container_of() allows us to put superclasses anywhere. To make your code more robust, you should always use container_of() instead of relying on a superclass being the first member, even when you use single inheritance.
Interfaces
An interface, can be thought of as just a class with a vtable only (only behaviour, no state). Thus, we already have all the tools to emulate interfaces in C! In fact, languages like C++ or python don’t have a concept of interfaces. It’s just another data-less class you can extend.
The cost of dynamic dispatch
The fact that we access our methods through functions pointers gives us a great deal of flexibility, but it also adds a runtime cost. Mainly, we have to follow pointers to get the function’s address, which often causes a cache miss (doubly so when using vtables), which can severely worsen CPU utilization. If that wasn’t enough, the compiler also can’t know the underlying function being called at by statically looking at the code, so it cannot inline the function.
These runtime costs are well known. OOP compilers can perform optimization to reduce these costs (an obvious one is to not use a vtable if a class has only one method), but they can only do so much when OOP requires such flexibility. We simply have to live with them.
Should I write C code like this?
I suggest you only write code like this when you need to. In most cases you don’t need any of this OOP stuff while writing C. In the common case you already know your data and the necessary function calls at compile time. If you write in this style when you don’t need to then you’re wasting your time, the CPU’s time, the user’s time, and the time of anyone else reading your code (including future you). Even when you need some form of polymorphic behaviour on your own types. A simple switch statement on a tagged union is computationally faster and cognitively simpler when you have control over the variants. If you badly want to use OOP, then use a language that has first-class syntactic support for it to avoid all the boilerplate you’ll have to write.
Dynamic dispatch is still valuable. I find it useful at the boundary of APIs, like when writing a library or needing to process custom programs from the user such as when loading plugins in an extensible program.
Conclusion
Rejoice, for we too, have grasped the procedural reality behind OOP. Many important code bases like the Linux kernel and GTK use these techniques, so what we discussed is applicable to real C code.
You now possess what an undergraduate textbook considers eldritch knowledge. No longer shall we be at the mercy of abstractions imposed on us through ideologically motivated programming languages. Part of the journey of being a programmer is having the courage to stare at the incomprehensible, and have the patience to grasp it. I encourage you to continue exploring other incomprehensible abstractions in the future.